本文共 7152 字,大约阅读时间需要 23 分钟。
译者:andy huang
Yahoo的流计算引擎对比测试
(雅虎Storm团队排名不分先后, , , , , Mark Holderbaugh, , , , and
免责声明:2015年12月17日的数据,数据团队已经给我们指出,我们不小心在Flink基准测试中留下的一些调试代码。 所以Flink基准测试应该不能直接与Storm和Spark比较。 我们在重新运行和重新发布报告时已经解决了这个问题。
更新:2015年12月18日有一个沟通上的误解,我们运行的Flink的测试代码不是checked in的代码。 现在调试代码已经删除。数据团队检查了代码,并证实它和目前的运行的测试是一致的。 我们仍然会在某个时候重新运行它。
摘要-由于缺乏真实世界的流基准测试,我们比较了Apache Flink,Apache Storm和 Apache Spark Streaming。 Storm 0.10.0/0.11.0-SNAPSHOT和 Flink 0.10.1 测试表明具有亚秒级的延迟和相对 较高的吞吐量, Storm 99%情况下具有最低的延迟。 Spark Streaming 1.5.1支持高吞吐量,但是具有相对 较高的延迟。
在雅虎,我们已经在一些日常使用中支持我们的商业开源的大数据平台上投入巨资。 对于流工作负载,我们的首选平台一直Apache的Storm,它取代了我们的内部开发的S4平台。 我们一直在广泛使用Storm,目前雅虎运行Storm节点的数量现在已经达到了2300个(并且还在不断增加中)。
由于我们最初使用 Storm是在2012年决定的,但目前的流处理系统现状已经发生了很大的改变。 现在有几个其他值得关注的竞争对手包括 Apache Flink,Apache Spark(Spark Streaming),Apache Samza,Apache Apex和谷歌的Cloud Dataflow。 有越来越多的议论探讨哪个系统可以提供最佳的功能集,哪一个在哪些条件下性能更好(例如见 , , ,还有 )。
为了给我们的内部客户提供最好的流计算引擎工具,我们想知道Storm擅长什么和它与其他系统相比哪些还需要提高。 要做到这一点,我们就开始寻找那些可以为我们提供流处理基准测试的资料,但目前的资料都在一些基本领域有所欠缺。 首先,他们没有任何接近真实世界的用例测试。 因此,我们决定写一个并将它开源。 在我们的初步评估中,我们决定在我们的测试限制在三个最流行的和有希望的平台(Storm,Flink和Spark),但对其他系统,也欢迎来稿,并扩大基准的范围。
基准设计
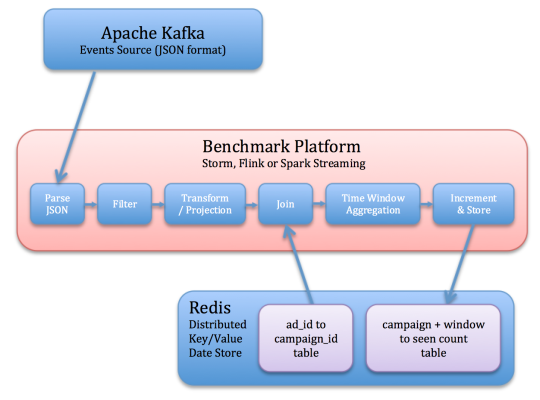
基准的任务是从Kafka读取各种JSON事件,确定相关的事件,并存储每个campaigns活动相关的事件转换成Redis的时间窗口计数。 这些步骤试着侦测数据流所进行的一些常用的操作。
操作的流程如下(和在下面的图中示出):
- 读取Kafka事件。
- 反序列化JSON字符串。
- 过滤掉不相关的事件(基于EVENT_TYPE字段)
- 取相关字段的快照(ad_id和EVENT_TIME)
- ad_id及其关联的campaign_id加入每个事件。 这个信息被存储在Redis中。
- 每campaign活动一个窗口计数,每窗口计数存储在Redis中,附带最后更新的时间戳。 此步骤必须能够处理延迟的事件。
输入数据有以下模式:
- USER_ID:UUID
- PAGE_ID:UUID
- ad_id:UUID
- ad_type:字符串在{ banner,modal,赞助搜索,邮件,Mobile}
- EVENT_TYPE:字符串在{视图,点击,购买}
- EVENT_TIME:事件发生时间戳
- IP地址:字符串
生产者创建带有创建时间戳标记的事件。 截断此时间戳到一个特定的,这个特定的数字给出了时间窗口和事件所属的开始时间 ,在Storm和Flink中,虽然更新Redis是定期的,但常常足以满足选定的SLA。 我们的SLA为1秒,因此我们每秒一次往Redis写入更新的窗口。 Spark由于其设计的巨大差异,操作上略有不同, 有一个关于在Spark部分的更多细节是我们与数据一起记录时间,并在Redis中记录每个窗口的最后更新时间。
每次运行时,程序会读取Redis的Windows和Windows的时间窗口并比较它们的last_updated_at次数、产生的延迟数据点。 因为如果上次事件窗口不能被发送(emit),该窗口将关闭,一个窗口的时间,其last_updated_at时间减去其持续时间之差表示是在窗口从给Kafka到Redis期间通过应用程序的时间。
window.final_event_latency =(window.last_updated_at – window.timestamp) – window.duration
这一个有点粗糙,但这个基准测试并没有对这些引擎定义窗口数据粒度的粗细,而是提供了他们行为的更高级视图。
基准设置
- 10秒时间窗口
- 1秒SLA
- 100 个 campaigns 活动
- 每次campaigns 活动有10个事件
- 5 个 Kafka与5个分区节点
- 1 个 Redis节点
- 10个工作节点(不包括像Storm的Nimbus协调节点)
- 5-10 个Kafka生产者节点
- 3 个ZooKeeper节点
因为在我们的架构中,Redis的节点使用一个精心优化的散列方案,仅执行内存查找,它并不会成为瓶颈。 节点被均匀配置,每一个节点有两个英特尔E5530 2.4GHz处理器,总共16个核心(8物理核心,16超线程)每节点。 每个节点具有24GB的内存,机器都位于同一机架内,通过千兆以太网交换机相连。 集群共拥有40个节点。
因为单个生产者最大每秒产生约一万七千事件,我们跑了Kafka生产者的多个实例,以创建所需的负载。我们使用在这个基准测试中利用了20到25个节点(作为生产者实例)。
每个topology使用10个worker,接近我们看到的雅虎内部正在使用的topology的平均数目。 当然,雅虎内部的Storm集群更大,但是它们是多租户并运行着许多的 topology。
Kafka开始基准测试时会被清空数据,Redis填充了初始数据(ad_id到campaign_id映射),流作业开始后会等待一段时间,让工作完成启动,让生产者的生产活动稳定在一个特定的速率,并获得所需的总吞吐量。 该系统在生产者被关闭之前会运行30分钟。停止前允许有几秒钟的滞后以让流工作引擎处理完所有事件。 基准测试工具运行会生成含有window.last_updated_at的列表的文件– window.timestamp数据。 这些文件被保存为我们测试各个引擎的吞吐量并用来生成这份测试报告中的图表。
Flink
该基准测试中, Flink 使用Java的DataStream的API实现。 该Flink的DataStream中的API和Storm的API有许多相似之处。 对于这两种Flink和Storm,数据流可以被表示为一个有向图。 每个顶点是一个用户定义的运算,每向边表示数据的流动。 Storm的API使用spout 和bolts 作为其运算器,而Flink使用map,flatMap,以及许多预建的operators ,如filter, project, 和 reduce。 Flink使用一种叫做检查点,以保证处理它提供类似Storm的ACKING担保机制。 我们跑这个基准测试时Flink已默认关闭检查点。在Flink中值得注意的配置列表如下:
- taskmanager.heap.mb:15360
- taskmanager.numberOfTaskSlots:16
该Flink版本的基准测试使用FlinkKafkaConsumer从Kafka读取数据。 数据在Kafka中是一个JSON格式的字符串,然后由一个定制的flatMap operator 反序列化并解析。 一旦反序列化,数据通过自定义的过滤器过滤。 之后,经过滤的数据,通过使用project 投影(projected )。 从那里,将数据由自定义的flapMap函数产生Redis的数据,最终的数据计算结果写入Redis。
在该Kafka发出的数据事件到Flink基准速率从50,000个事件/秒到17万次/秒变化。 对于每个Kafka发射(emit)率,Flink完全处理元组的百分比与延迟时间的基准示于下图。
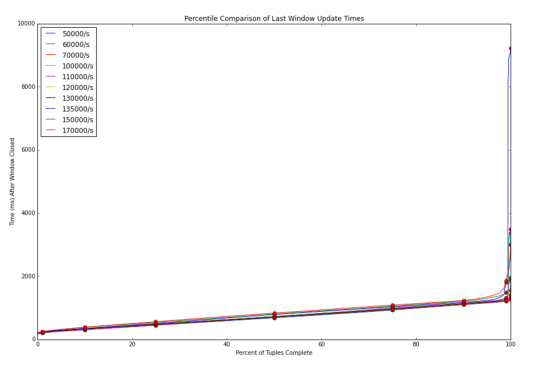
延迟在所有Kafka 发射(emit)率是相对一致的。 等待时间线性上升,直到大约第99百分位数时(约1%的数据处理时间),延迟出现成倍的增加(1%的数据处理延迟远远大于99%的数据)。
Spark
Spark基准代码用Scala编写。 由于Spark的微批处理方法和Storm的纯流计算引擎性质不同,我们需要重新考虑基准实现的部分。 为了满足SLA, Storm和Flink每秒更新一次Redis,并在本地缓存中保留中间值。按此设计,Spark Streaming 的时间批次被设置为1秒,这会导致较小的吞吐量,为此我们不得不扩大批次的时间窗口以保证更大的吞吐量。
基准用的是典型Spark风格的DStreams。 DStreams是流数据,相当于普通RDDs,并为每个微批次创建一个单独的RDD。 注意,在随后的讨论中,我们使用术语“RDD”而不是“DSTREAM”来表示在当前活动micro batch中的RDD。 处理直接使用Kafka Consumer 以及Spark1.5。 因为在我们的基准中Kafka输入的数据被存储在5个分区,Kafka消费者创建具有5个分区的DSTREAM。 在此之后,一些变换施加在DStreams,包括maps 和 filters。 涉及与Redis的交互数据的变换是一种特殊情况,因为我们不想每次记录Redis就创建一个单独的连接,我们使用一个mapPartitions操作,可以给RDD代码整个分区的控制权。 通过这种方式,我们创建一个连接到Redis的单一连接,并通过该连接从Redis中查询在RDD分区中的所有事件信息。 同样的方法在以后我们往Redis写入最终结果的时候使用。
应当指出的是,我们的写入Redis的方式被实现为RDD变换,以维持基准测试的简洁,虽然这不会与恰好一次的语义兼容。
我们发现,Spark没能保持主足够的高吞吐量。 在每秒达到100000消息时延迟大大增加了。 我们认为需要沿着两个方面进行调整,以帮助Spark应付增长的吞吐量。
第一是microbatch持续时间。 这个控制维度不存于像Storm纯流计算引擎系统中。 增加持续时间同时也增加了等待时间,这样就减少(调度)开销并因此增加了最大吞吐量。 挑战是,在处理吞吐量延迟最小化和最优批持续时间之间调整是一个耗时的过程。 从本质上讲,我们要选择一个批处理时间,运行基准30分钟,检查结果,并减少/增加批持续时间。
第二个是并行度。 增加并行度似乎简单,但对Spark来说做起来难。 对于一个真正的流计算引擎系统像Storm,一个bolt 实例可以使用随机洗牌(reshuffling)方式发送它的结果到其它任何数量的bolt 实例。 要扩大规模,增加第二bolt 的并行度就可以。 Spark在一样的情况下,我们需要执行类似于Hadoop的MapReduce的程序决定整个集群合并洗牌操作, 但reshuffling 本身引入了值得考虑的开销。 起初,我们以为我们的操作是计算密集型(CPU-bound)的,为较多分区做reshuffling相对reshuffling 自身的开销是利大于弊,但实际上瓶颈在于调度,所以reshuffling 只增加开销。 我们怀疑高吞吐率的操作(对spark来说)都是计算密集型的。
最后的结果很有趣。 不同的窗口持续时间下Spark有三种不同的结果。 首先,如果批处理的窗口持续时间设定得足够大,大部分事件都将在当前微批处理中完成处理。 下图显示了这种情况下,得到百分比加工图(100K事件/10秒窗口持续时间)。
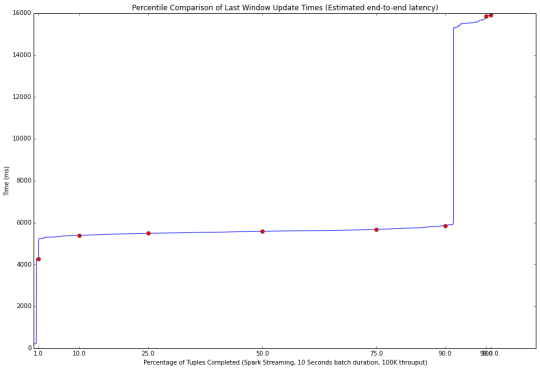
90%的事件在第一个微批处理中被处理,这就有了改善延迟的可能性。 通过减少批处理窗口持续时间,事件被安排至3到4个批次进行处理。 这带来了第二个问题,每批次的持续时间内无法处理完所有安排到该时间窗口中的事件,但仍是可控的,更小的批处理窗口持续时间带来了更低的延迟。这种情况示于下图(100K事件/3秒窗口持续时间)。
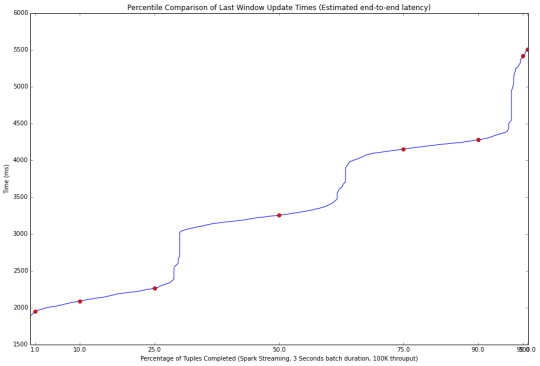
最后,第三个现象是当Spark Streaming 处理速度跟不上时,基准测试的输入数据需要入队列并等待几分钟以让Spark 完成处理所有的事件。 这种情况示于下图。 在这种不良的工作方式,Spark溢出大量的数据到磁盘上,在极端的情况下,我们最终可能出现磁盘空间不足的情况。
最后要说明的是,我们试图在Spark1.5中引入的新背压(back pressure)功能。 如果系统是在第一工作区域,背压没有效果。 在第二操作区域,背压导致更长的延迟。 第三操作区域结果显示背压带了副作用。 它改变了批次的长度,此时Spark处理速度仍然跟不上, 示于下图。 我们的测试表明,目前的背压功能并没有帮助我们的基准,因此我们禁用了它。
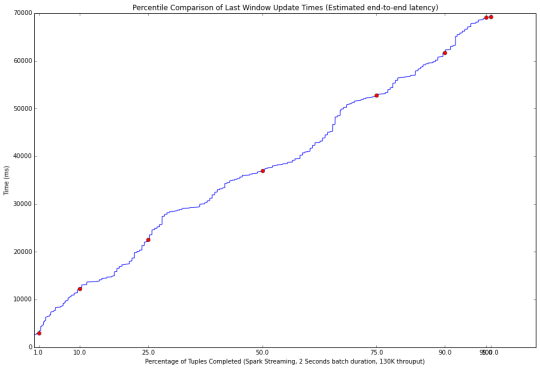
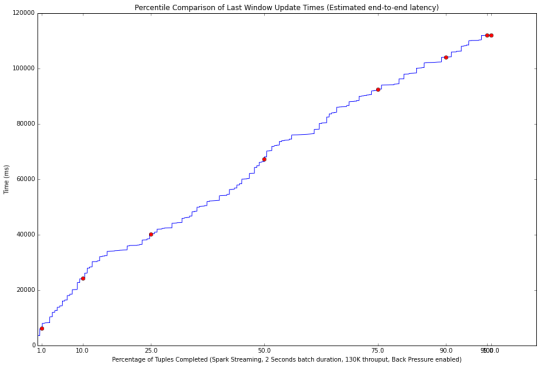
无背压(上图)的性能,以及与背压启用(下图)。 启用背压后延迟性能较差(70秒VS 120秒)。 注意,这两种的结果对流处理系统是不可接受的,因为数据处理速度都落后于 输入数据的速度。 批处理的时间窗口设定为2秒时,具有130000的吞吐量。
Storm
Storm的基准测试使用Java API编写。 我们测试了Apache的Storm 0.10.0 和 0.11.0-Snapshot版本。 Snapshot commit hash是a8d253a。 每个主机分配一个工作进程,每个worker给予16 tasks 以运行16个executors ,也就是每个cpu核心一个executor。
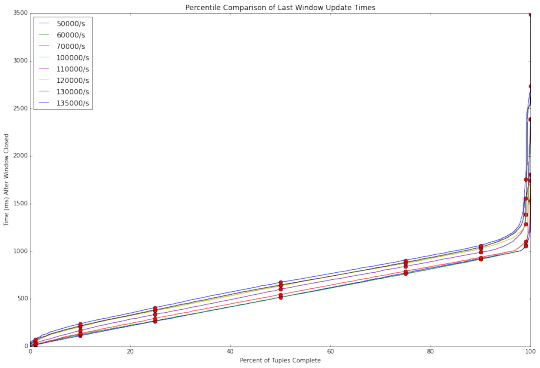
Storm0.10.0:
Storm0.11.0:
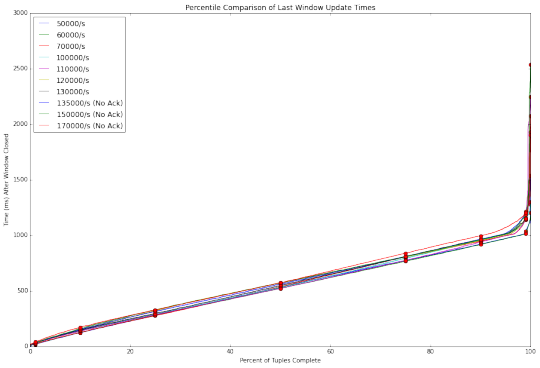
与Flink和Spark Streaming相比,Storm毫不逊色。 Storm 0.11.0 优于 Storm 0.10.0,显然0.11.0对0.10.0版本做了优化。 然而,在高吞吐量上Storm的两个版本依旧捉襟见肘, 其中Storm 0.10.0 无法处理超过每秒135000事件的吞吐量。
Storm 0.11.0同样遇到了瓶颈,直到我们禁用ACKING。 在基准测试Topology中,ACKING用于流量控制而不是处理担保。 在0.11.0中,Storm增加了一个简单的背压控制,使我们能够避免ACKING的开销。 随着ACKING启用,0.11.0 版本在在150,000/s的吞吐量测试上 /比0.10.0 -稍好,但依然很糟糕。 随着ACKING被禁用,Storm在高吞吐量上比Flink的延迟性能要好。 不过注意的是,随着ACKING被禁用,报告和处理的元组故障的功能也被禁用。
结论和未来工作
下图比较这三个系统的测试结果, 我们可以看出,Storm和Flink两者具有线性响应。 这是因为这两个系统是一个一个的处理传入事件。 另一方面,在Spark Streaming 依据微批处理设计, 处理是逐步的方式得到结果。
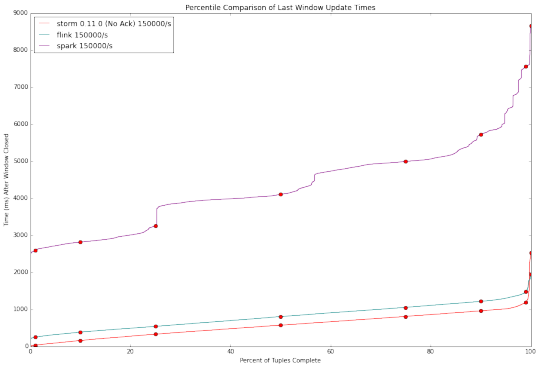
吞吐量VS延迟曲线图在系统对比中差异也许是最明显的,因为它总结了我们的研究结果。 Flink和Storm具有非常相似的性能,而Spark Streaming,需要高得多的等待时间,但能够处理更高的吞吐量。
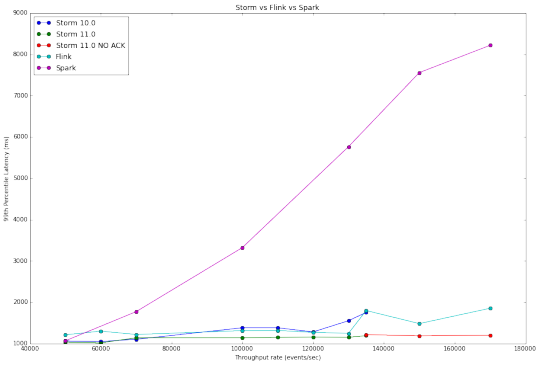
超过每秒135000的事件中不包括 Storm0.10.0和0.11.0在ACKING启用时的结果,因为他们处理速度无法跟上吞吐量。 由此产生的图形中Storm0.10.0 在45000毫秒时结束测试, topology 跑的时间越长,得到越高的延迟,这表明它性能在降低。
所有这些标准,除非另有说明, Storm,Spark,和Flink均采用默认设置进行,我们专注于撰写正确的,容易理解,无需每次优化的,以充分发挥其潜力的方案。 由于这种每六个步骤都是一个单独的bolt或spout。 Flink和Spark的aggregation合并操作是自动的,但Storm(非trident)没有。 这意味着对Storm来说,事件经过更多的步骤,相比于其他系统具有更高的开销。
除了对Storm进一步优化,我们想扩大在功能方面的测试,并在测试中包括像Samza和Apex 等其他流处理系统,未来也会把容错性,处理担保和资源利用率作为测试的基准。
对我们来说 Storm 足够满足要求。 拓扑结构写起来简单,很容易获得低延迟, 和Flink相比能得到更高的吞吐量。如果没有ACKING,Storm甚至在非常高的吞吐量时击败Flink,我们期望进一步优化bolts组合,更智能的tuples路由和改进ACKING,让Storm ACKING启用时可以在非常高的吞吐量时与Flink相竞争。
近来实时流计算引擎系统之间的竞争日趋白热化,但并没有明显的赢家, 每个平台都有各自的优点和缺点。 性能只是其中之一,其他如安全、工具集也是衡量因素。 活跃的社区为这些和其他大数据处理项目进行不断的创新,不断从对方的进步中受益。 我们期待着扩大这个基准测试并测试这些系统的新版本。
转载地址:http://ifrzx.baihongyu.com/